모던JS 챕터5 사이트를 따라 읽으며 메모한 내용
- 원시값의 메서드
본문에서 원시값에 대해 설명 중. 아주 앞에서 본 초기 자료형인 원시값이다.
옛날엔 6개였는데.... Symbol 때문에 7개로 늘었다.
심볼은 진짜 특이한 녀석이야. 아직도 적응 안되긴 하는데, 모르는 사이 조금씩 쓰고 있었고.. 조만간 익숙해질 것 같다고 생각한다.
객체에 대해서도 설명 중...
객체에 대한 개인적인 생각은 늘상 객체를 사용하면서 느끼는 거지만, 다른 언어에 비해 정말 간편하고 뭐든 구겨넣을 수 있어 좋지만, 잘못쓰면 더럽고, 다른사람도 알아보기 힘든 곤란한걸 만들 수 있기 때문에 주의해야한다는걸 느낀다.
- 원시값을 객체처럼 사용하기
해당 챕터에서는 설명이 좀 긴데, 한줄요약하면
원시값을 잘 쓰기 위해 (잘 가공하기 위해) 도와줄 수 있는 방법을 고민했고, 래퍼 객체(원시값들을 서포트하는... 즉 감싸는 랩으로 감싸듯 둘둘 래핑하는 래퍼객체)를 붙이게 되었다.
그러니까, 중간 처리는 임시로 객체이지만, 최종적으로는 원시값으로 되돌려주니 이런 제목이 붙은 것 같다.
하단에 ⚠️부분에서 생성자로 new(또 새로운 객체 생성) 키워드 써서 "신규객체"로 만들어 쓰지 말라고 경고한다. 원시값 반환할까? 생각하지만 그게 아니라 타입을 찍으면 어쨌든 신규로 만든 객체이니까... 이부분만 주의하면 될 것 같다.
⚠️⚠️ 두번째로 나오는 부분은 한번 고민해보자.
(=> 별로 조작할 일이 없으니까 메서드도 안만든거겠지?)
- 숫자형
숫자형에 대해 설명을 하고 있다. 다른 언어에서 하다 온 사람은, 혹은 처음 접하는 사람은... 아 범위가 매우 크긴 한데, 일단 범위가 있구나. 정도로만 이해하고 넘어가도 좋을 것 같다.
그리고 더 큰 숫자를 받기 위해 최근 추가 된 bigInt라는 자료형도 추가되었다고하니, 나중에 알려준다고.
빠르게 읽고 넘어가자.
중/고등학교 때 지수표현식에 대해 배웠을 것이다. 많은 자리의 숫자를 표현하는 것에 어떻게 할 것인가 고민을 하다가 나온, 과학적표기법=지수표현식 ko.wikipedia.org/wiki/%EA%B3%BC%ED%95%99%EC%A0%81_%EA%B8%B0%EC%88%98%EB%B2%95
을 코드로 표시한 것이니, 필요할 때 사용하면 될 것으로 보인다.
- 16,2,8진수
숫자의 표현 방식에 대한 부분이고, 솔직히 이 부분에 대해서는 본문에서 깊이 다루지 않고 있는 것 같다.
m.blog.naver.com/theo5970/221840365072
나도 별로 적을 내용이 없으니... 위 블로그 혹은, 구글검색으로 "진법에 대해서" 라고 검색해서 참고하도록 하자.
우리 사는 세상은 10진법, 컴퓨터가 생각하는 세상은 2진법. 정도로 요약. 색상표현은 16진법을 주로 쓰고.
- toString(base)
이거 이거, 설명이 좀 갑자기 튀어 나오긴 하는데,
위에랑 연결해서 말하면, 지금 튀어나온 이 항목은 숫자형의 래퍼객체 중, toString 이라는 녀석을 설명하고 있다.
그러니까 숫자형을 도와줄 수 있는 친구이며, (base)값에 따라 진법을 변환 해 줄 수 도 있다고 설며 중. (base의 기본값은 우리가 흔히 접하는 10진법이라고 써있군.)
⚠️숫자는 점 두개! 숫자는 점 두개!!!!! 아니면 괄호로 묶어서 호출
본문에 잘 설명을 해 두었으니, 실수하지말자... 실수랑 헷갈리는 실수.
- 어림수 구하기
아 이거 정말 많이 써야하니 두번봐도 안 부족하고 기억해 두면 좋은 래핑객체의 메서드 친구들이다 ㅠㅠㅠㅠ 정말 고마운 친구들
소수부 자르고 정수부만 남기는 trunc 는 ie에서 안먹으니까 폴리필 만들어서 처리할 것.
if (!Math.trunc) {
Math.trunc = function (v) {
return v < 0 ? Math.ceil(v) : Math.floor(v);
};
}별건 없다. 없으니까 Math 객체에 추가해줘서 잘 돌게 해줬다고 보면 된다.
- 부정확한 계산
바로 위에서 어림수 구하기 많이 쓴다고 했는데, 그게 이거 때문이다..... ㅠㅠㅠㅠㅠㅠ
ㅠㅠㅠㅠㅠㅠ....
ㅠㅠㅠ 왜 그... 늘 묻는것이 소숫점을 더하면 계산이 틀려요? 인데, 다른언어에서도 발생하는 실수형 계산의 문제이다.
각 언어별 부동소수점 실수형 문제에 대해 처리 결과를 샘플로 보여주는 아주 좋은 사이트
한번 놀러가서 구경 해 보자.
=> 정말 짧고 간단하게 설명을 하면, 2진법이란 영역에서는 10진법의 0.1이라는 수를 정확하게 저장할 수 없으니, 대~~~충 어림수를 구해서 (손실을 각오하고) 잘라버려서 원하는 결과를 얻고 있다는 것...
특히 실수형을 다룰 때는 꼭 잊지말고, 기획자와 어느정도 선에서 정밀도를 조율할지 꼭 논의하도록 하자.
언젠가 IEEE-754 지수부/가수부에 대해서도 한번 보면 좋을 것 같다.
당장 들어가진 말고... en.wikipedia.org/wiki/IEEE_754#2019
요건 한국어 버전 : ko.wikipedia.org/wiki/IEEE_754
오, 요즘은 위키백과에서 64비트 레이아웃도 보여준다. 영어로 되어있지만 구경가보자. : en.wikipedia.org/wiki/Double-precision_floating-point_format
어지럽다. 계산기나 전자상거래 만들 분들은 꼭 꼭... ..
아무튼 .. 그리고 JS에서 0과 -0은 동일하게 취급하고 있고 ...
- isNaN 과 isFinite
숫자가 아닌가?, 유한인가!
많은 설명이 필요하지 않은 좋은 메서드 친구들이다.
주로 두가지의 특수한, 정상적이지 않은 숫자형의 상태를 체크할 때 써야한다.
1. 숫자가 아니거나
2. 무한하거나. ^^ (양으로 무한, 음으로 무한.. 인..피니티!)
(!) 부분에 Object.is 와 비교하는 부분이 있는데, 일단 나중에 또 나올 것으로 보인다.
본문에서 설명한 두가지 엣지케이스에 대해서만 기억 해 둘 것. (= NaN비교와 0, -0 를 오브젝트is로 비교 한 결과에 대해서 )
- parseInt와 parseFloat
파스한다 정수형
파스한다 실수형
파스 = 구문 분석. 파싱 = 구문분석을한당
즉, 정수형 구문으로 분석을 해서 쪽 뽑아내 내가 정수형을 원하면 너에게 가져다 주겠다.
- 기타 수학 함수
사실 Math에 너무 많음.
developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/Math
진짜 많음.
그치만 .random()은 정말 잘 쓰임.
max, min도 많이 쓰고
pow... 는... 나만 안쓰는 것 같다.
- 문자열
스트링이라는 문자배열에 대한 이야기.
'문자' 를 나타내는것이 별도로 존재하지 않으니, 그냥 한 글자만 있어도 문자 배열의 가장 조그만한 배열을 쓰는구나. 하고 이해하면된다.
자 본문에 보면 3가지 따옴표 뭐 표현 방법이 나오는데, 백틱을 요즘 많이 쓰니까, 백틱표현을 어떻게 하는지 눈여겨 보면 도움이 많이 될 것이다.
백틱은 다른말로 백쿼터 라고도 부르기도 한다. 나이드신분들은 리눅스 백쿼터 백쿼테이션 이라고 부르시더라.
- 특수기호
이부분도 꼭 한번 읽고 넘어가면 좋다.
캐리지 리턴이란것이 있는데, 일단 고대의 유물 타자기라는 전설적 기계에서 나온 유물이라 요즘은 맨위에 줄바꿈만 해도 잘 된다고 생각해도 무관하긴하다.
... 간혹 리턴을 안하면 출력 라인이 꼬이는데, .. 일단.. 아직까지 브라우저에서 본적은 없는 것 같다.
뭐 나머지들은 특수문자를 그냥 쓰면 입력이 안되니까 저렇게 써야한다고 가이드를 해 준 부분이니 기억해두자.
- length 는 프로퍼티인거도 기억해두면되고... (함수아니니까 실행하려 들지 말 것)
- 특정 글자에 접근하기
문자 배열이라고 했으니까, 배열 접근하듯이 접근하고, 이터레이션(뺑뺑이)돌릴 려면 돌릴 수 있다는 내용을 설명 중.
charAt가 좀 더 안전성있긴 하다는 점. 기억해두면 되고...아 이건 뭐 구현 목적에 따라 다를 것 같은데....
undefined 에러가 나야하면 [] 로 접근하자.
- 문자열의 불변성
문자배열로 한번 할당해두면 직접접근해서 수정이 불가능하다는걸 이야기한다.
- 대소문자 변경하기
영어의 대소문자를 변경할 수 있는 메소드를 2개 제공 해주고 있다.
- 부분 문자열 찾기
substring 이라고 하는데, 몇가지 있으니 한번 보고 가자.
- str.indexOf
못찾으면... 아~ 나는 못찾았으니 인덱스가 -1이다 하고 반환해주는 친구
indexOf(찾아야하는 문자열, 시작위치 position) 라고 볼 수 있다. 기본 위치는 당연히 0부터 시작한다. (글자보다 앞에 커서위치로 보자.)
str.indexOf(searchValue[, fromIndex])아, 엠디엔엔 위에처럼 되어있다. (뒤가 옵셔널)
- 커서가 뒤 부터 시작해서 찾아들어가는 lastIndexOf 도 있다.
- 비트연산자를 사용한 기법 (부분 일치 문자열)
이건 잘 안쓰이긴 하는데, ~str.indexOf 로 들어가서 -1 이상의 값으로 떨어지면, 일치하는 문자열이 있다는 소리고, 위치도 알 수 있다.
-1이면 시작부터 맞다는 소리.
0이면 어디도 없다. + 문자열이 긴 경우 오류가 발생할 수 있음.
- includes
많이쓴다. 있는지 없는지만 받을 때 쓴다.
- startsWith
잘 안쓰긴 하는데, 정규표현식 쓰기 싫을 때 쓴다. 시작하는 글자가 이게 맞는지 할때.
- endsWidth
마찬가지다. 끝나는 글자가....ㅎ
- 부분 분자열 추출하기
아주 많이 많이 쓰인다. substring, substr, slice
본문과 다르게 ㅋㅋㅋ 메소드 길이순서대로 나열해보았다.
slice - 범위 지정 반환인데, 끝부분을 위치를 지정하면 (양수인 경우 얼마나 선택해서 반환할지이고, 음수면 끝에서 뒤부터 해당위치까지 반환하는 특징이 있다.) 끝부분을 지정 안하면 끝까지 간다.
substr - 시작 포지션부터 지정한 길이(음수포함)만큼 추출하는 친구
substring - (음수는 0으로 취급하는 특이한 녀석) slice 와 비슷한데, end에 음수를 사용못해서 뒤집어 역선택이 불가능한 부분이 있는걸 알면 쓰기 쉽다. 실수나 오동작을 안하려면 이쪽을 개인적으로 요걸 자주 쓰고있다.
- 문자열 비교하기
문자열은 아스키 코드에 대응된다고 예전에 한번 쓴 것 같은데......... . . . 아 요즘은 유니코드....
같은 영글자의 대문자가 더 크단걸 기억해두면 좋고...
유니코드 전환도 가능하고
- 문자열 제대로 비교하기
부분은 지금은 좀 넘어가자. 다양한 표기법이 있고, 각 국가별로 다룰 내용도 참 많다. localeCompare 는 지금보다 밑에가서 배열 메서드 부분에서 한번 더 다루자.
- 심화 서로게이트 쌍(Surrogate pair)
스킵. 일단 간략하게 문자 표현의 사이즈 문제로 표시 불가능한 문자에 대해 좀 더 많은 부분을 쓴다. 정도로 하고 넘어갈 것.
자세하겐 못파고 있는데, 일반적인 문자는 길이가 1인데, 저런 서로게이트쌍에 포함되는 글자는 길이가 2가 되어 출력된다.
서로게이트쌍으로 표현한 기호라서 그렇다는데...
스킵! 자세한게 알아보고싶으면 직접 찾아봐야할 것 같은데,.. 아.. 나 몇년전에 분명 이 문제 때문에 QA에서 20글자 카운트 어쩌구 안들어간다고 뭐라 그래서 어떻게 해결했던거 같은데 기억이 잘 안나네.
(였는데 하단에 추가 메모 해 둠.)
- 발음기호와 유니코드 정규화
유니코드 UTF-16의 빈 부분을 추가해서 데코레이션 하여 발음기호를 만들고 조합을 하여 하나의 문자로 만드는 부분인데,
윗점 아랫점 순서를 다르게 붙이면 다르다고 인식하니까 (보기엔 같은데말이지) 노멀라이즈(일반화)해서 같은건지 보자는 거잖아.
써로게이트 쌍보다 낫네.
>>> 써로게이트상을 알기 위해 유니코드를 친절하게 가르쳐주는 국민대 소공 강승식 교수님의 강의를 보고와서 적겠다.
그냥 넘어갈 사람은 아래까지 쭉 넘어가도 좋다.
와 이런걸 유투브에 올려놓아주시다니 너무 감사하다. 정말...
덕분에 유니코드에 대해 레벨업 한 느낌.. 빅데이터나 머신러닝, NLP 등 CS(computer science)기초 지식을 다루는 추가적으로 다른 강의들도 너무 좋아보였다. 시간날 때 마다 꼭 봐야지
아니 그래서 그러니까... 유니코드 인코딩종류가 있는건 알았고. 주로 가변3바이트 문제 때문에,
ㅠㅠ 회사에서는 디비 만들때 이모지가 깨지지 말라고 가이드로 제발 4바이트짜리 UTF8mb4(utf8mb4_general_ci) 를 mysql를 주로 썼으니...
BMP랑 SMP라는 개념이 있었구나... 세상에... ((BOM은 (Byte Order Mark))
다국어 기본 평면과 / 다국어 보충평면이 존재하고. 65536이면 문자를 다 표현할 수 있다는 말도안되는 생각을 했구나.
대부분이 CJK라는 차이나 제팬 코리아 통합한자들로 이루어졌고... 한글 11172자 만 넣어도 넘쳐서 폐기.
4바이트로 작업하기 시작했구나. (21비트까지 정의...!)
일반적으로 나머지들은 2바이트 안에 작업되어 있고(BMP), 17-21비트까지 추가적인 동아시아 코드가 들어있는 (SMP) 라고 하는구나..
ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C_%ED%8F%89%EB%A9%B4
오옹...신기함.
유니코드 평면
위키백과, 우리 모두의 백과사전. 유니코드 평면은 유니코드 전체를 논리적으로 나눈 구획을 말한다. 0번(다국어 기본 평면)에서부터 16번까지 모두 17개로 나뉘며, 각 평면은 65536개(216개)의 코드
ko.wikipedia.org
음음... 이거 한중일 통합한자 정리한사람 머리 빠게졌었겠네.
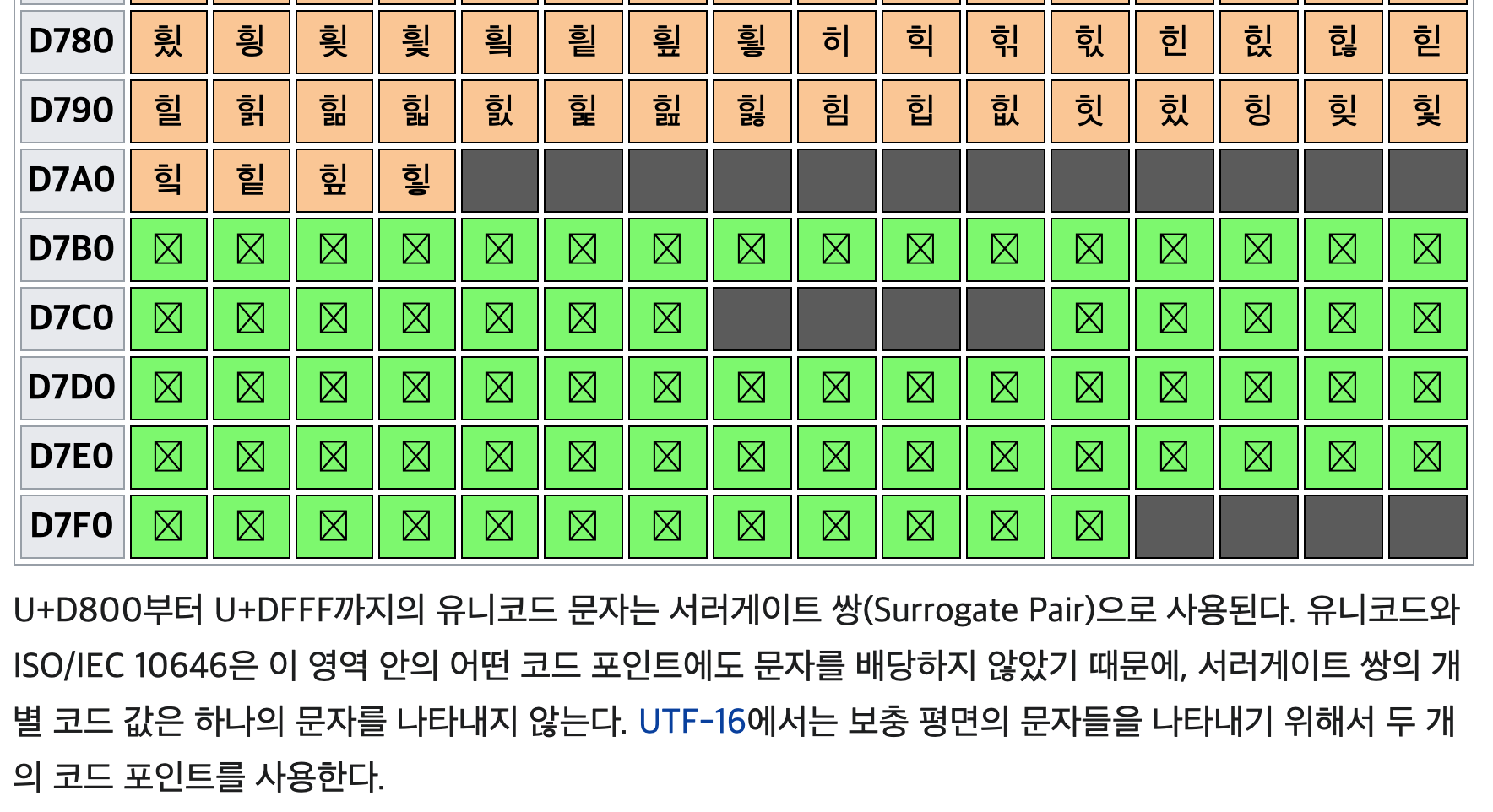
한글이 여기서 힣으로 끝나는구나. 음, 유니코드랑 - KS 완성형 부분은 필요없으니 넘어가고...(코드테이블로 코드 변환프로그램 작성)
유니코드 각 문자에 대한 정수값으로 매핑을 하면 21비트 내에서 표시가 가능하다이건데, 통상적으로... ㅎㅎ
근데 보통 바이트 단위로 기록하니까 몇바이트로 해야하는 문제가 발생하게 되었고 9ㅁ9
그 방법론이 UTF-인코딩 방식이 된거였다.
UTF-8 (in web) : 1-4 바이트 단위로 구현 (가변길이로 구현하는 방식이 ㅠㅠㅠ 이것이었다 ㅠㅠㅠ아이고 이모지야 ㅠㅠㅠ)
2번 강의 10분에 좋은 내용이 나온다. 한글은 3바이트 인코딩으로 거의 다 커버되는구나.
영어권 사용자들은 아스키 쓰고 있으니, 완벽한 호환성을 자랑하는군. 단점은 저장공간 낭비고. 문자열 처리가 간단하지 않다.
UTF-16 (window, java ) : 2 or 4 바이트로 구현 - 둘중에 하나임. BMP 아님 SMP
그래서 서로게이트쌍인지 써러게이ㅌ쌍인지 (본론은 여기부터)
위에서 BMP 영역 중 (D8-DF) 영역을 써로게이트 영역이라고 하는데 2048개로 미리 빼놓았고.
SMP 판에는 1024*1024 해서 100만자(1,042,576)가 정의 되어 있다.
-> 요기서 100만자를 2바이트의 쌍으로 표현 하고 싶다는게 요지인데,
아 미쳤다 ㅋㅋㅋㅋㅋㅋㅋ 와 이게 이렇게 되는구나!
->> ㅎㅎ 위에서 미리 빼놓은 2048개 ㅋㅋ BMP 영역을 둘로 쪼개서
앞부분을 high 서로게이트 라고 정의하고 1024개 D800 - DBFF
뒷부분을 low 서로게이트 라고 정의하고 1024개 DC00 - DFFF
나눠서 SMP영역에 대응 되는 코드를 불러 오도록 하는 주소부 할당 기법이었던것이다...
그래서 SMP 영역에
첫번째 글자는 D800DC00
두번째 글자는 D800DC01
이런식으로 소환해서 백만자를 표현할 수 있으니... SMP판의 주소를 4바이트(16비트"쌍")로 만들 수 있어서 ㅋㅋㅋㅋ 와

21비트를 (계산편하게 하나 버리고) 20비트로 만들어서 + 12 비트 더해서 32비트 4바이트 조합으로 대응한다는게 원리구나.
그러니까 JS에서 반으로 쪼개면 SMP영역에 도달할 수 없으니 정상적인 글자가 안나오지 -ㅁ-.... 길이는 당연히 2개짜리가 되어야 정상이고
따라서 본문에 있는 사용빈도가 낮은 상형문자 중국어를 예시로 한번 해체해보면 이상한 기호가 출력된다는걸 말하고 있다.


UTF-32 (unix) : 아예 4바이트로 구현 => SMP 포함인듯? 강의가 끝나버렸네! ㅋ
--------------
넘어갈 사람은 여기까지 넘어오면 된다. 원문에서 어렵게 써놓아서 직접 찾아보게 하다니 속이 시원...
다음 페이지로 넘기자.
- 배열
배열 어레이. 배열 생성방법엔 늘 두가지가 있는거 익숙하니 넘어가고... 인덱스를 기반으로 하는 접근 방법에 설명을 하고 있다.
컴퓨터는 주로 숫자에 대한 인덱스 순서를 0부터 시작하니까 이제 좀 자연스럽게 익지 않았을까.
본문에서 배열 선언 방법에 대해 설명에 대해 알려주고 있다. 생성자로 초기화 하는 방식은 잘못 사용하면 문제가 생길 수 있으니 유의.
하단에 new Array() 라는 부분에서 나올텐데 예를들면 공간에 대한 초기화만 하고 주소부 데이터를 할당 안하면 길이는 2인데 내용은 접근하면 데이터를 할당 안했으니 언디파인드가 없는 문제가 생긴다. 자바나 다른 언어에서는 문제를 뾰롱 뾰록 내겠지만...
가능하면 90% 이상은 대괄호로 그래서 선언하는거같다.
넣을 수 있는 자료형은 제약이 없다는거 알아두고, trailing 쉼표는 일단 저렇게 붙일 수 있지만 특정 팀이나 회사의 룰에따라 제거하는게 lint로 적용될 수 도 있으니 그냥 이렇게도 쓸 수 있다. 하고 넘어가자.
- pop·push와 shift·unshift
배열 이야기하면서 큐 나 스택 이야기를 하고 있는데, 자바스크립트의 배열은
데큐다. ( 간단하게 요약하면 스택 + 큐 = 데큐 ) -> 고민이 되고 잠시 하늘을 보고 한숨이 들면 자료구조에 대해 알아보는게 좋다.
혹은 일단 넘어가거나 본문내용을 종이에 따라서 그려보면 된다. 잘 설명해주고 있긴하다.
왜 저걸 밑에 적어놓아서 처음보는 사람 헷갈리게 하는지ㅎ...
일단 큐나 스택에서 사용하는 방법을 배열에서 사용할 수 있다는걸... "갑자기!?" 설명하고 있다.
큐 -> 뒤에서 밀어넣는(끝에 데이터를 추가흐는) 푸시와 맨 앞에 (인덱스가 0인 숫자)를 제거하는 시프트로 구성
스택 -> 위에 나온 뒤에서 밀어넣는 푸시와 끝에 넣은 친구를 팝~ 하고 빼주는 팝이 있다. pop인지... 폽인지 퐙인지 알아서 읽...
그럼 하나 빠졌는데 맨앞에 역으로 (인덱스가 0인 숫자)에다가 꾸겨밀어 넣어주는 것이 있지 않을까?
그래서 unshift 라는 언시프트가 있다.
- 배열 내부 동작 원리
차근차근 읽어보면 별 문제 없을 것 같다. 참조를 통해서 배열 객체가 있는 부분을 하나 더 만든거니까 둘이 같은 배열 데이터 주소 영역을 참조하며 바라본다는 내용과 중간에 있는 내용은 배열을 쓸데없이 객체처럼 활용해서 오동작을 만들지 말라고 경고하는 내용이다.
- 성능
아... 이건 정말 그려보거나, 공간박스 (이삿짐박스)에 맨 밑에 들어있는 책이 0이라고 생각하면 미친듯이 공감하면서 이해야가 쉬워진다.
본문이 잘 설명 해두었다.
- 배열 친구의 반복문
for 사용법을 복습한다.
배열은 in으로 돌리지 않는걸 추천하는데, 쓸 때는 써야한다. 나중에 거품물며 싸우지말자.
앞에서 객체할때 말했는지 모르겠지만 말버릇처럼 말하는 팁인데,
오브젝트를 오브로 돌리려 하지말고 (안도니까),
인덱스가 있는 배열(유사배열포함)을 인으로 돌리려 하지 않는다면 평온을 얻을지어다.
...
너무했나?
- ‘length’ 프로퍼티
멀쩡한 프로그램이라면 length를 읽는 곳에만 쓸 것 이다. 쓰기가 가능하지만.. 싸우지말고 지양하면 괜찮을거 같기도하고
아 맞아 근데 arr.length = 0; 이라는 코드를 만났을 때 당혹감이란..ㅎㅎ;
보통은 배열 참조하는 변수를 []로 새로 할당해서, 기존에 배열이 들어있는곳을 알아서 청소하고 외딴섬으로 가비지로 만든다.
언제나 사람의 취향차이는 존중하자.
- 다차원 배열
설명이 짧네, 우리 사는 세상의 위도 경도 같은걸 저장할때 쓰면 좋다.
2차원 이상의 배열이다.
- toString
배열을 빠르고 깔끔하게 출력하는 방법이다. 가끔 오브젝트가 끼어있으면 출력안되기도..
아무튼 배열 부분은 끝! 메서드로 넘어가보자.
- 배열과 메서드
에 대한 내용 중 요소 추가·제거 메서드 는 했던 내용이고
아.. 배열의 메서드를 못쓰는 경우가 있다. 본문에서 중간에 유사배열인 경우인데, forEach 같은게 돌고 싶어도 안돌때가 있다. 브라우저에 따라 될 수 도 있던가? 나중에 어딘가에서 이야기할텐데, 배열 객체에서 빌려와서 렌탈을 한다거나하는 식으로 순회할 수 있긴하다.
( Array 객체가 어디까지 기본적으로 탑제되어있는지... 확인을 해야.. isArray 같은것도 .. 나왔으니, 유사 배열여부는 쉽게 체크 되겠지 )
- splice
delete 랑 설명하면서 문제점을 보여주며, splice를 씁시다. 하고 강의 중이다.
원본이 되는 배열을 재설정하고
- slice
이 친구는 원본이 되는 배열은 보존하고 새로 값을 만들어주니, 자른 후, 원본을 덮어쓰거나 (가능하면 안하는게좋지), 잘라 둔 값을 가공된 내용이라고 잘 이름을 지어둔 변수에 담아서 사용하도록 하자.
- concat
원본이 보존된다. 연결하고 합치고 내부에 배열이 있으면 복사도해서 새로 가공해서 잘 쓸 수 있도록 도와준다. 잘 가공해서 이름 잘 지어서 담아서 써주자.
유사 객체는 사용에 유의...
거기다가 Symbol.isConcatSpreadable 값이 true 라면 프로퍼티 값을 주워간다고 써있긴한데, 이거도 잘 만들어진 유사 배열이어야지 동작 안하기도한다. (쉽게말하면 0으로 시작하는 인덱스 같은 숫자로 시작하는 key가 있어야한다.)

저런 식으로 잘못 만들면, empty 같은걸 만들어서 참조 오류같은 문제를 만들 수 있으니 잘 합치자.
- forEach 로 반복하기
배열을 돌면서 출력하자. 본문의 예제를 따라 해 보자.
- 배열 탐색하기
- indexOf, lastIndexOf와 includes
indexOf랑 라스트인덱스 오브는 검색 순서 차이 뿐이고,
결국 값이 있으면 인덱스 위치표시해주는 좋은 친구, 없으면 -1
인클루드스는 포함되어있는지 반환할 뿐이군.
- find와 findIndex
이게 좀 쓸만한 메서드 친구다.
객체로 구성된 배열을 돌면서 내부를 탐색하려면 for 2번을 쓰기도 하는데, 요걸로 하면 깔꼼하거든.
(...얼리 리턴 좋아하는 분들이 잘 쓰던데)
파인드 인덱스는 또 위치를 돌려주는 친구다.
- filter
뭐라고 하면 처음보는 간단하게 사람들에게 와 닿을까..., 위에 find의 진화버전? ㅎㅎㅎ
조건이 맞으면 즉시 결과를 돌려주는(비슷한걸 얼리 리턴이라고 했던가) find와 다르게 거름망에 필터로 걸러서, 싹 다 홅어서 필요한 내용을 반환하는 친구가 필터친구다.
- 배열을 변형하는 메서드
- 맵 map
말을 좀 어렵게 써놓았네. 위에서 본 filter 같은 기능을 직접 만들 수 있다는거다.
1. 첫번째 예제는 return 을 꼭 써서 result에 원하는 값을 배열로 반환 받을 수 있는 예제고
2. arrow function을 쓰면 return 을 쓰지 않아도 lengths 에 반환이 되니, 저렇게 써 둔 예제.
- sort(함수)
원본 배열 자체가 변경된다.
숫자 예시를 들어서 비교 문제에 대해 언급 중이니 기억해두자.
즉, 숫자정렬을 sort로 바로 하면 안된다. - 그래서 본문 하단에서 이걸 사전 편집 순으로 요소 정렬이라고 설명하고 있다.
그래서 위에 (함수) 라고 써 준 부분으로 정렬조건에대한 함수를 만들어서 숫자오름차순 기준 정렬을 적용하는걸 보여준다.
(!) 로 각종 방법에 대해 설명 중.... 앗 ^^; 위에서 스킵한 localeCompare 내용도 다시 나오네...
동등레벨로 비교하는 부분이 참 좋은 예제라 여기서 보는게 좋다.
- reverse
역순 정렬인데, 아까 위에 sort(함수) 처럼 compareFunction 영역이 없어서 좀 쓰기 좀 그렇다 ^^;
- split 와 join
split : 문자열을 특정한 패턴으로 잘라서 배열화, + 길이제한이 가능한 친구
join : split 의 반대, 아무것도 안하면 문자열로 붙에고, 패턴을 인수로 넘기면 그걸로 접착제 역할
- reduce와 reduceRight
본문 설명이 좀 부족한데, 리듀스는 보통 4개의 인수가 있다.
accumulator - 지금까지 누적된 계산을 합친 결과 (누산합)
item - 현재 배열 요소인 아이템
index - 현재의 인덱스
array - 원본이 되는 배열
이렇게 네개를 가지고 뱅뱅뱅뱅 반복을 돌게된다.
누산값을 초기화 하는 옵셔널로 initial 값이 있는데, 비어있는 배열을 돌리자고 하면 없이 호출하면 오류가 난다.
빈 경우 예외처리로 누산 옵션을 0으로 넣는다거나 하는 방법이 예외처리법으로 쓸 수 있기도.
즉, 오류없이 빈 배열을 돌아도 초기값을 394 로 해두면 누산 결과로 394를 뱉는다.
아무쪼록 잘 쓰길... 리듀스는 (함수)를 받을 수 있는데, sort처럼 가공안하고 원하는 결과(??) 라는걸 나오겠지 하고 그냥 쓰게되면...
-> 예를들어 문자열 중간에 넣으면 누산이 아니라 toString 같은 결과를 얻으니 알아둘 것.
거기다 초기값까지 0으로 해두면 0 + "문자열" 이 붙는 골치아픈 상황까지 완성~
잘 가공해서 쓰자.
리듀스라이트는 배열의 오른쪽(?) 끝에서부터. 동일한 수행을~
- Array.isArray로 배열여부 알아내기
배열도 객체니까 할말이 없긴한데, 유사배열인지 순혈 배열인지 알아보는 방법이 이것이다.
- 배열 메서드와 'thisArg'
콜백용으로 써야하는데, 일단 스킵~ this 위치에 대해 익숙해지면 이해가 될 것.
users.filter(army.canJoin, army) 로 쓰는게 더 명시적인 이유가 현재 this 위치를 army 에 있는것으로 쓰겠다고 하는거라 그렇다.
뭐 일단 익숙해질때까지 스킵
- iterable 객체
순환 가능한 뺑뺑이 돌 수 있는 객체에 대해 이야기 하고 있다.
그렇다면 반복문 for ... of를 쓸 수 있다고 이야기를 하고 있고, 나는 오브젝트는 이터러블 하지않으니 못돌린다고 말버릇처럼 말하고있고...
배열은 이터러블한 객체!
문자열 이터럽르한 객체!
좋다ㅋㅋㅋ
아... 전에 심볼이라는 친구로 여러 각종 외부 컴포넌트같은거 네임스페이스 형태로 만들 수 있다 했던가... 본문 참 길게 이터러블 이란 녀석의 심볼을 한번 만들어보려고 하네! + _ + 따라해보자.
음... 이터러블한 객체는 from 이랑, to랑 next랑 done 라는 정보를 가지고 있다는걸 설명을 좀 해줘야지
그 이터레이션 프로토콜에 대해 검색 해 보자. (이터러블 프로토콜, 이터레이터 프로토콜) 이걸 준수해야한다.
넘 복잡할 수 있으니 지금은 ... 어? 하고 머리아프면 넘어가자.
다시 돌아와서 읽었을 때 이해하면 그걸로 더 성장할 수 있다.
- 이터레이터를 명시적으로 호출하기
여기도 설명이 좀 부족해서 어쩔 수 없다. 위에 내용이랑 비슷하다. 문자열로 실험을 해 본 것이다.
- Array.from
위쪽에 배열과 메서드에서 언급한 내용이다. 빌려온다는 표현을 쓰긴 했는데, 유사 배열인 친구들도 돌고 싶으면 돌려야할 때가 있다.
Array.from을 이용해서 깔끔한 새 배열 객체로 만들어주니, 돌릴 수 있는것이다.
서로게이트쌍에 대해서는 위에 설명했으니 문제없겠지?
멍하다면 위로 올라가서 주황색 부분을 읽거나, 넘어가자.
- 맵과셋
이터러블한 객체 순회에서 쓴 맵 메서드랑은 다르다.
새로운 자료구조를 가지는 객체들이다. 특징은
맵 - 배열과 비슷하지만 키와 벨류로 순서쌍으로 된 자료형.
셋 - 맵과 비슷하지만 순서가 의미 없는 중복을 허용하지 않는 값의 모임(set, 세트? 본문의 컬렉션?).
- 맵
객체도 키가 될 수 있는 특징일 가진 자료구조
순서가 있다고 map[key] 같은 접근하는게 불가능하지 않지만 제발 순서로 접근하지 않으면 좋겠는 자료구조.
set을 이용해 key, value 를 잘 저장하자.
map.set(key, value)
map.get(key)
map.has(key)
map.delete(keyl)
map.clear()
- 셋
중복을 허용하지 않은 특별한 컬렉션이고, 이터러블 객체를 받으면 담아서 내부에 저장한다.
순서에 의미가 없다했는데 넣었다고 값이 사라졌다고 하면 곤란하다.
set.add
set.delete
set.has
set.clear
set.size
---
set.keys - 셋 내 모든 값 포함
set.values - 맵과 호환성
set.entries - 맵과 호환성
맵과 비슷하게 위의 메서드를 잘 활용 되고,
- 구조분해 할당
즐겨 쓰는 기능 중 하나이다.
구조분해 할당인데, 이거 이용하면 짥고 빠르게 내용을 할당할 수 있다.
아, 잘못쓰면 에러가날 수 있으니, 순서를 잘 기억하고 있거나 오류가 없을 것 같고 정확하게 반환되는 경우 연계해서 쓰자.
- 배열 분해하기
선언 된 배열을 신나게 쪼개보자. let 뒤에 대괄호를 이용해서 공간을 만들고, 변수명을 입력해서 할당한다.
그럼 각 인덱스에 일치하는 내용이 들어가게 되는데, 안 맞는 경우 선언이 안되었으니 undifined 가 되는걸 기억해두자.
(!) 빈 쉼표를 사용해서 띄워 줄 수 있고 할당을 스킵해서 할당할 수 있다.
(!) 할당연산자 우측엔 모든 이터러블이 올 수 있다.
반복 가능한 객체면 다행이도 분해해서 할당하는게 된다는걸 이야기하고 있다. 예제에 있는 내용은 셋이니까 중복없이 할당되겠지.
(!) 좌측에는 뭐든 할당 가능
객체의 프로퍼티 에다 할당하는 짓도 가능하다는걸 보여주고 있네..... ㅎㅎㅎ
(!) 쩜 엔트리스()로 반복하기
해당 객체의 어떤 엔트리들이 있는지 k, v 로 받아볼 수 있는 메서드였는데, 이걸 써서 반복돌리면서
오브젝트를 배열화 하고, -오브젝트는 of로 돌리지 말 것-
배열에 있는 내용을 분해! 할당! key, value 로 해당 반복에서만 사용하는 스코프를 가진 채 출력하는 놈을 만들었다.
(!) 변수교환 트릭
구조분해 할당의 트릭으로.. 개발자가 자리를 옮길 때, 이젠 3개의 의자가 필요 없다.
...

...
... 로 나머지 요소 가져오기...
...
할당하고 싶은 변수에 할당 한 친구 말고 남는 친구들은 ...나머지새로운배열 에 담아서 다양하게 활용할 수 있다.
... 은 마지막에 있어야 한다는 것. 혹은 아예 처음부터 쓰던가.
- 기본값
위에서 할당이 안되면 undefined 라고 했으니, 기본값을 지정한다는 내용.
- 객체 분해하기
지금까지는 배열을 분리했으니 객체도 분리해보자는 것.
사용법을 한번 쭉 살펴보면 양만 많지 위에 배열 분리 잘 따라왔다면 비슷하게 분리되는걸 알 수 있다.
(!) let 없이 사용하기 - 가독성이 안좋아서 조심해서 쓸 것. 실행구문으로 감싸서 문법오류를 피하자는 내용.
- 중첩 구조 분해
영어로 nested destructuring 라고하는데 살다보면 어떤 사람들은 '네스티드' 항목들, 네스티드 객체 라고 부르고 있더라고. 이부분이다.

다른것은 다 괜찮아 보이는데, extra (할당 연산자 좌측의 패턴에는 없음) 이라고 표시되어 있는데, 요걸 제외한 부분이 거슬린다.
설명을 따라가면 네스티드 된 객체를 해체해서 네스티드가 아닌 변수들로 뽑아서 할당했지, 네스티드로 만든것이 아니다.
라는 걸 알 수 있다. 그래서 전용변수(초록색으로 된 네모)가 없다고 이야기 하고 있다.
- 똑똑한 함수 매개변수
어떤 함수에는... 매개변수가 많다고 한다. => 그렇지.. 만들기 나름이니까 말이다.
이 중에는 디폴트가 지정되어있으면 선택적으로 골라서 넘기면 되는 부분을 설명하고 있다.
중첩객체와 콜론을 조합해서 기본값을 피하면서(undifined 로 작성한 부분) 넘어가는 부분들을 이야기 하고 있으며,
마지막 항목에서 매개변수에 = {} 를 디폴트로 먹여서, 객체가 들어가지 않아도 디폴트로 객체로 먹이는 방식을 하고 있는데..
그냥 에러내고 예외처리하는게 안전하지 않을까 싶기도 하고, 개인의 구현 선택과 프로젝트 방향과 가치관에 맡기겠다. 이건....
- Data 객체와 날짜
날짜다 젤 복잡고 어렵고 힘들고 눈물나는 자바스크립트 날짜다. 다양한 국가별 시간에 대응해야하고, 각종 표시기법, 포멧팅 방법 등등을 다루긴 하는데
옛날에는 이런 번잡한 컨트롤이 어려워서 moment.js 라던가를 써서 쉽게 해결했고 (요즘은 쓰지 않는 추세)
요즘은 day.js day.js.org/ 같은걸 사용해서 해결하고 있지만 여기선...
배운다.
- 객체 생성하기
new Data()
새로운 시간 객체의 메세드를 호출해서 동작을 시켜주고,
이거 만들어서 뭐하니, 보통은 let now 라고 결과를 현재 시간을 가져오는 용도로 쓴다.
시간은 자리 timestamp 라고하는 unix 타임스탬프 기준으로 좀 가공해서 사용하는데, 보통 10자리(초) 13자리(밀리초-밀리세컨드)를 쓴다. 아래쪽에서 한번 더 보자.
UTC 라는 부분이 나오는데, 이건 타임존에 대한 부분을 설명 해야하고, 한국 타임존이 일단 +9인걸 아는 사람들은 OK
영국 그리치니 천문대 기준 시간이 +0 인지 알면 오케이.
모르는 경우 구글에서 "UTC 타임존" 이라고 쳐서 학습을 하고 오는것이 좋다.
아
우리는 계속해서 new를 사용해서 필요할 때 마다 조작할 시간 객체를 새로 생성해서 사용할건데,
Data를 내장 객체를 직접 건드리는 일을 별로 발생하지 않을 것으로 보인다. (해당 웹앱이나 어디에서 Date 내장객체에 뭔가 기능을 추가해 가면서 까지 쓰려면 해야지... 그래야 먹고살지)
- new Date(밀리세컨드)
UTC+0 기준에 대한 내용이네. 0 이라는 기준 시간은 1970년 01월 01일 0시 0분 0초 (영국시간)을 나타낸다고 보면 된다.
date.getTime() 을 쓰면 13자리 밀리세컨드로 된 현재 시간을 가져올 수 있다고 하단에서 다룬다는데 별거 없다.
- new Date(datestring)
구문을 분석해서 날짜로 만들어주는 방법이다. 현재 지역의 타임존이 나온다.
- 날짜 구성요소 얻기
날짜 조작 방법 중 주의 해야할 부분은... (0월 ~ 11월 부분)
그리고 getDate() ... 전체 날짜를 가져오는게 아니다. 일 만 가져온다. 와 getDay() - 숫자로된 요일 -_- ... 0이 일요일인 것...
'프론트 > 모던JS요약' 카테고리의 다른 글
| 모던JS딥따이브 독후감(1) - 19장 프로토타입까지 (0) | 2021.04.03 |
|---|---|
| 6장 - 함수 심화 학습(~나머지 매개변수와 전개 문법 까지) (0) | 2021.03.09 |
| 4장 - 객체(1) (0) | 2021.01.22 |
| 4장 - 객체(0) (0) | 2021.01.21 |
| 3장 - 코드품질(1) (0) | 2021.01.16 |